 枫言枫语
枫言枫语自动匹配(Auto-Exists)是DAX引擎的一个优化机制,主要目的是为了剔除无效运算来提升计算速度。但自动匹配的优化机制除了会影响底层实现外,它还会对计值环境造成影响,如果不理解这个机制的话很容易就会出现错误,特别是这个优化机制本身就存在Bug的前提下。
理解自动匹配
自动匹配原理很简单,可以用一句话来概述,即:在报表环境中,当同一个表上存在两个或以上的直接筛选器时,Auto-Exists 机制就会发挥作用,将自动剔除筛选器组合中的那些无效筛选组合以减少无效运算,从而达到提升运算效率的目的。
下面通过一个案例来辅助理解自动匹配的优化机制。如下图所示,模型中只有一个表,然后报表中存在两个切片器,分别筛选姓名和性别,然后度量值中先使用了ALL函数来移除姓名的筛选器,然后返回性别字段的可见数据,最终度量值只返回了性别为男的值。
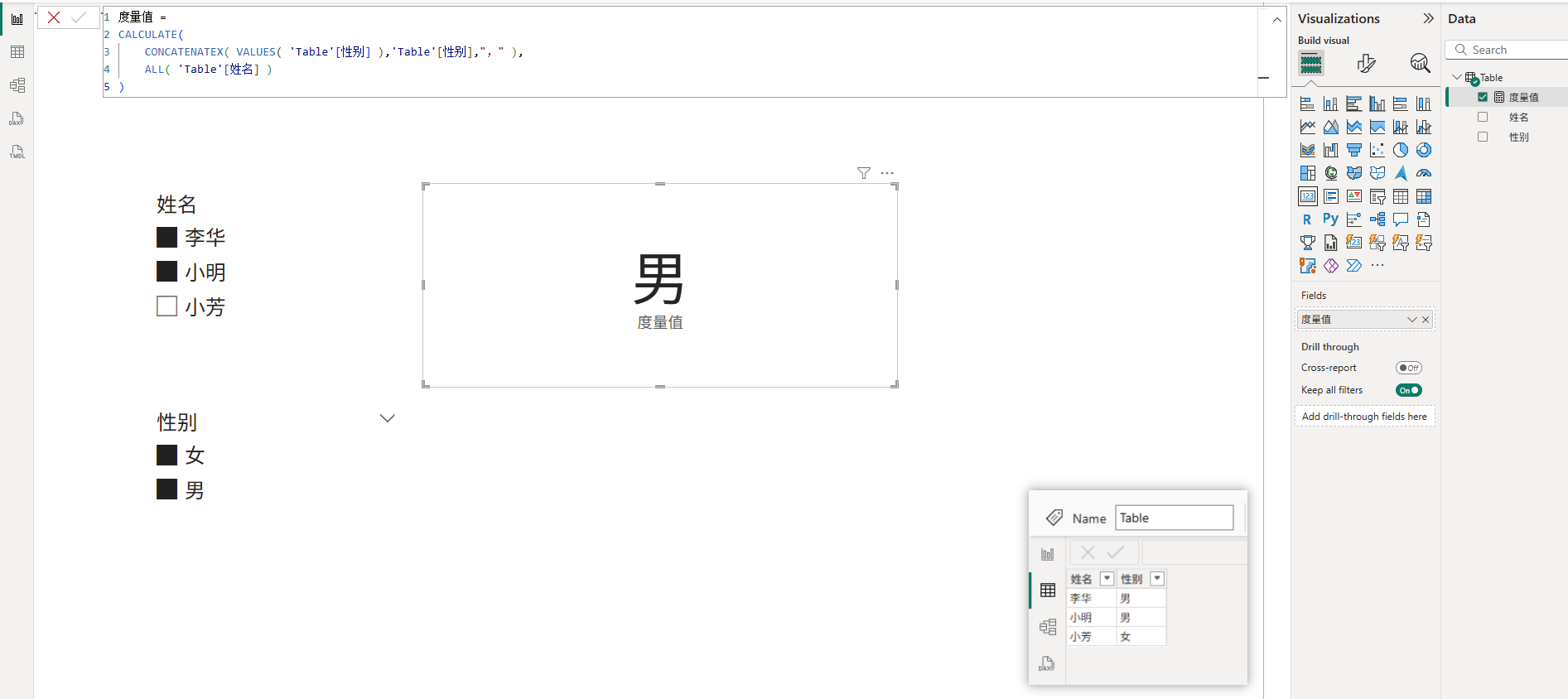
在上图这个案例中,理论上来说,当移除了姓名筛选器后,就只剩下性别筛选器了,那么性别字段的可见数据应该就是切片器里选择的项,即男和女,但度量值的结果却只返回了男,似乎与之前学习的筛选器交互等理论不符合。
实际上,由于姓名筛选器和性别筛选器都是来自同一个表的,所以触发了Auto-Exists机制,那些筛选不到数据的无效筛选组合被自动剔除掉了,所以最终度量值只返回男,而不是返回男和女。具体计值流程如下图所示:
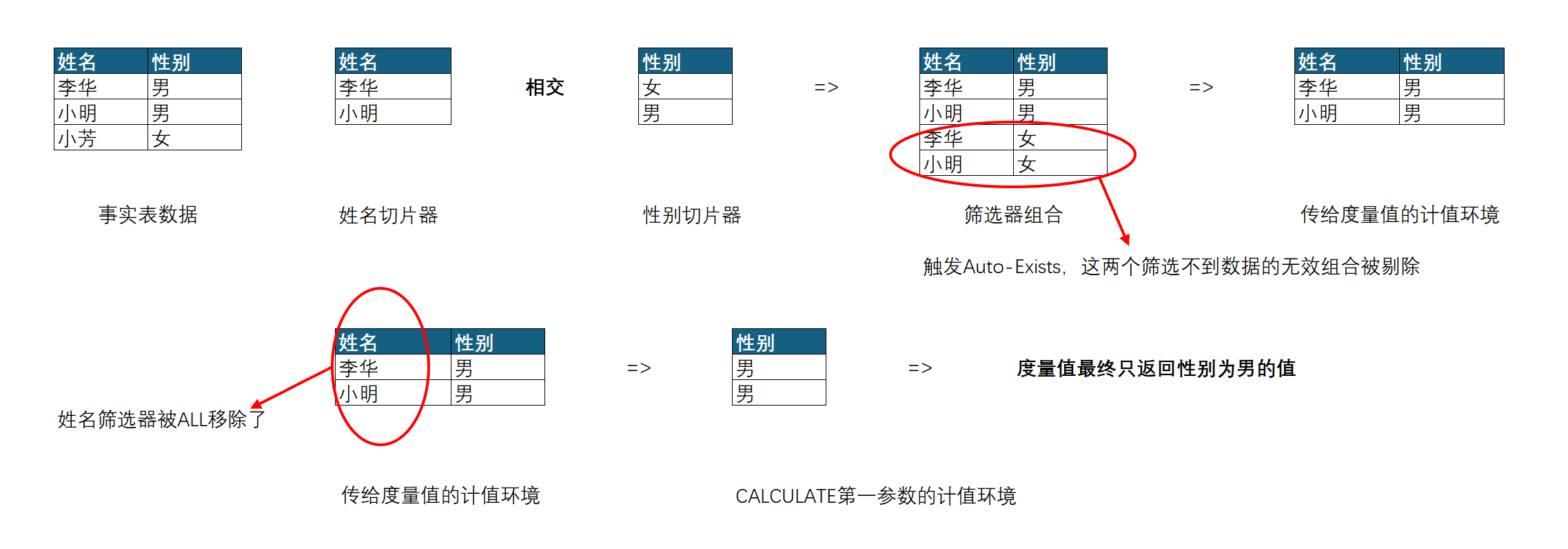
以上案例中,因为两个筛选器都来自同一个表,所以触发了Auto-Exists机制,而又因为姓名切片器中选择的都是男性的姓名,最终导致含有性别为女的筛选器组合被剔除了,使得最终结果只返回性别男。
但如果提取一个性别的维度表,让姓名和性别筛选器分别来自不同的表,就不会触发Auto-Exists机制,从而使度量值返回最开始预期的男和女两个值。如下图所示:

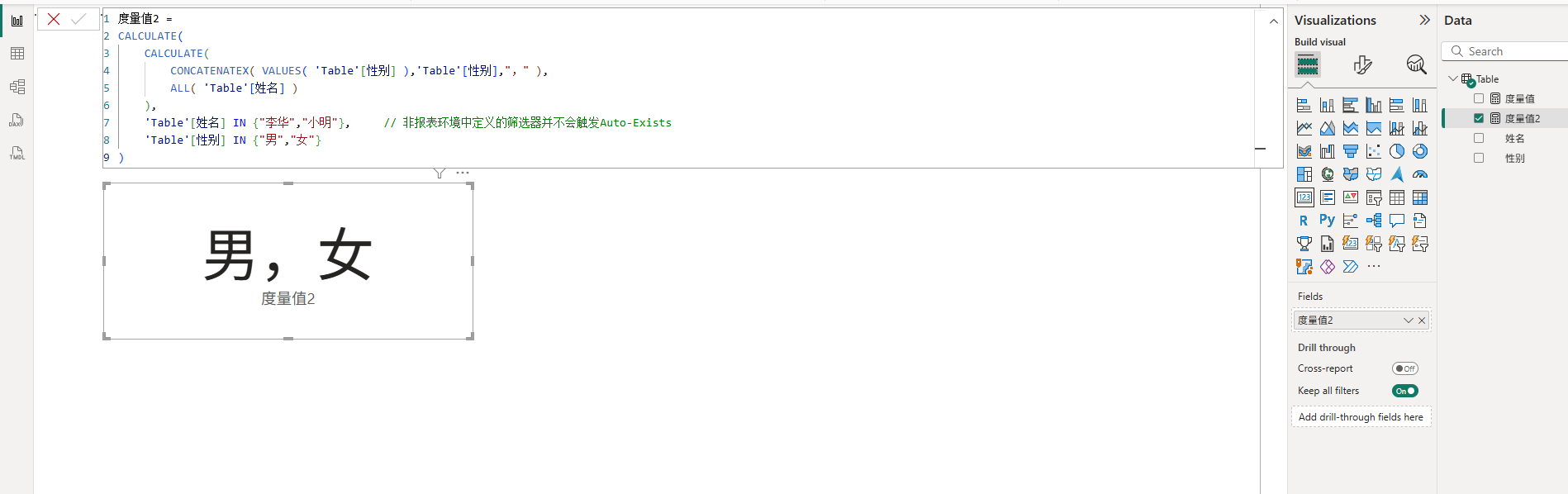
另外要注意的是,Auto-Exists机制是只针对报表环境的筛选器的,如果是在度量值的内部定义的筛选器,那是不会触发该机制的。比如下图所示的度量值,虽然存在同一个表上的两个直接筛选器,但由于其不是报表环境中的筛选器,所以不会触发Auto-Exists,因此度量值最终返回男和女两个性别。
自动匹配对视觉对象的轴字段的影响
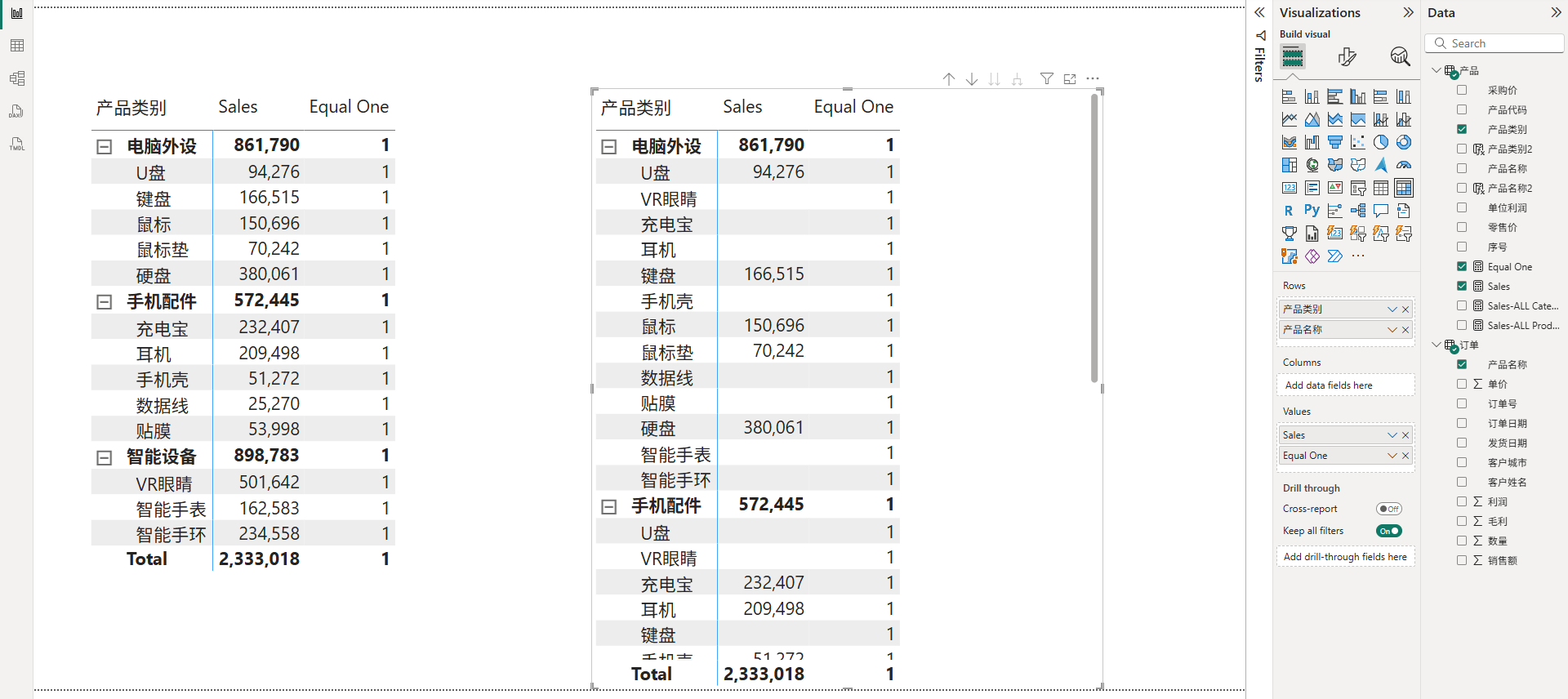
由于Auto-Exists机制是只针对报表环境的筛选器的,而报表环境中能够提供筛选器的除了切片器外,还有图表联动、视觉筛选器、视觉对象的轴字段等。所以矩阵的行列标签所提供的筛选器也是会触发Auto-Exists机制的,比如下图所示的矩阵中,行标签的产品类别和产品名称都来自同一个表,所以触发了Auto-Exists机制,导致每个产品类别下只存在该类别下的产品,而不会出现跨类别的产品。

其中,恒等于一的度量值的作用是为了让矩阵的每一行都有值,从而显示出所有行列标签的组合。因为矩阵有个特性,即整行或整列的值都为空的行或列会被自动隐藏。所以添加一个恒等于一的度量值,可以用来区分目前显示的行标签是不是完整的。
此时,如果将产品类别和产品名称字段分别放置在行标签和列标签里,那么就会出现一个奇特的现象,即存在完全空白的单元格,无论度量值表达式如何书写,该空白单元格中总是不会有任何值。如下图所示:

通过观察上图的结果,可以发现空白单元格的位置中产品类别和产品名称都是不匹配的无效组合,所以出现空白单元格只是因为视觉呈现要求的,其本质上已经被Auto-Exists机制给剔除掉了,所以无论怎么修改度量值都不会影响它,这些空白单元格的位置都总是空的。
然后,作为对比,如果行标签的产品类别和产品名称分别来自不同的表,那么就不会触发Auto-Exists机制,使得行标签的组合是完整的笛卡尔积组合,如下图所示:
此时,在那些产品类别和产品名称不匹配的组合中,就可以在度量值里通过移除筛选器等手段来控制计值环境,并使其返回所需的结果,这与前面触发了Auto-Exists机制后产生的空白单元格还是不一样的,需要注意区分。
总结
自动匹配(Auto-Exists)能够剔除无效筛选器组合,从而提升计算效率,但它也会对计值环境造成影响,因此在编写度量值表达式时需要时刻警惕这一个优化机制,否则很容易就会出错,这也是星型模型为什么更受欢迎的原因之一。




